

Self-driving systems are entering a different phase. The challenge is no longer about adding more cameras or writing better rules, but about building the infrastructure that turns enormous volumes of raw video into something a machine can actually learn from. Most of the conversation focuses on the models, the sensors, and the hardware. Far less attention is paid to the pipeline that makes all of this possible: the unglamorous, technically demanding process of transforming dashcam footage into structured training data.
That pipeline is where most of the real difficulty lies, and understanding it is key to understanding why some teams are accelerating and others are stuck.
Every moving vehicle with a camera is already producing data. Dashcams, surround-view systems, and purpose-built collection rigs generate hours of footage every day. Taken together across a large fleet, the volume is substantial. The natural instinct is to treat that volume as an asset.
The problem is that raw video, on its own, has no training value. A model cannot learn from an unstructured video file any more than a student can learn from a box of unsorted notes. Before footage can feed a training loop, it has to be ingested, cleaned, organized, tagged, and made queryable. That process is what a data pipeline does. And the quality of that pipeline, more than the sheer volume of footage collected, determines how useful the data actually becomes.
The common thread across every serious autonomy effort is clear: autonomous driving is now a data infrastructure problem, and the teams that solve it well are the ones that build better systems faster.
When footage arrives from the field, it arrives messy. Clips vary in resolution, frame rate, lighting conditions, and camera positioning. Files may be missing timestamps, GPS coordinates, or camera calibration data. Some clips will have motion blur, lens fogging, or obstructed views. Without consistent metadata, even good footage is hard to use systematically.

The first stage of a data pipeline is ingestion and quality filtering. Clips that fall below a usable threshold are discarded. The rest are standardized: normalized to consistent formats, timestamped, georeferenced, and tagged with basic environmental context such as time of day, weather condition, and road type. This sounds straightforward. In practice, it requires careful engineering, particularly when footage is coming from multiple hardware types across multiple geographies.
Privacy handling is also a requirement at this stage, not an afterthought. Faces and license plates captured in traffic are considered personal data under GDPR and equivalent regulations in other jurisdictions. For footage to be processed, stored, and shared legally, identifiable information must be blurred or removed before the data moves further along the pipeline. This step is now standard in compliant data operations, and it has to run automatically at scale.
Only after ingestion, quality filtering, and anonymization does the footage begin to resemble something usable. At that point, it is structured data. Before that point, it is just storage cost.
Structuring the footage is necessary, but not sufficient. For a model to learn from a clip, that clip needs semantic context. What is in the scene? Which objects matter? What is the vehicle doing, and what are the surrounding actors doing? Annotation is the process of adding that context.
For years, annotation was primarily a manual task. Human labelers would draw bounding boxes around vehicles and pedestrians, classify traffic signs, and mark lane boundaries frame by frame. This approach produces high-quality labels, but it does not scale. Annotating hours of driving footage by hand is slow and expensive, and the result still depends heavily on what categories the labeling team was asked to mark. Anything outside the predefined taxonomy is invisible.
Semi-automated approaches improved the economics considerably. Pre-trained detectors flag candidate objects automatically, and human reviewers confirm or correct them. The speed increases, but the fundamental limitation remains: the pipeline only finds what it was designed to look for.
Vision-Language Models change the calculus here. A VLM, in simple terms, is a model that can understand both video and natural language. Rather than running a fixed detector over a clip, a VLM can respond to open-ended queries: find clips where a cyclist crosses unexpectedly, or flag scenes with construction zones and poor visibility. That makes it possible to search and curate a large video archive without knowing in advance exactly what you are looking for. Without structure, a large video archive is not really a dataset. It is a warehouse. A VLM turns it into something usable.
This shift matters practically. Teams building training datasets can now start with a question rather than a category list, and use VLM-powered search to find relevant clips from footage that would previously have sat unused.
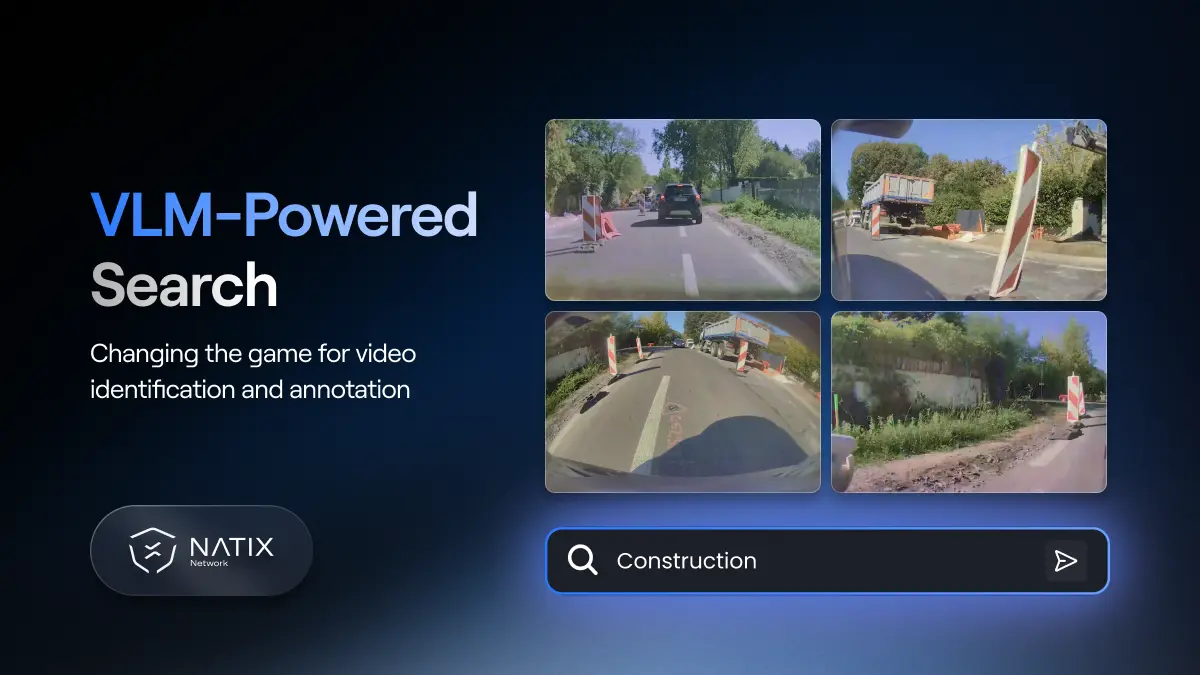
A system trained on normal driving can handle normal driving. The challenge is what happens in the long tail: the situations that occur infrequently but matter most when they do. A child running into the road between parked cars. A vehicle stopped in a live lane with no warning. An intersection where traffic signal behavior does not match the typical pattern. These are edge cases, and they are what separate a system that works in demos from one that is safe enough to trust at scale.
The real world does not cooperate. You cannot schedule rare events, and you cannot ask a fleet to encounter a specific near-miss scenario on demand. The more efficiently a team collects data, the more that data will reflect common conditions. Average data does not prepare a system for extreme variation.
This creates a genuine bottleneck. Dedicated survey fleets driving fixed routes in specific cities will accumulate enormous volumes of footage, but that footage will over-represent predictable, well-lit, well-marked driving conditions. The edge cases, by definition, are distributed unevenly across geographies, weather conditions, road types, and driver behaviors. Finding them requires both scale and diversity.
This is exactly why autonomous driving data collection at the level of individual vehicles, across many regions and conditions, produces something that centralized fleets struggle to replicate: a dataset that reflects the actual long tail of real-world driving.
Once footage has been ingested, anonymized, annotated, and curated, it feeds two distinct parts of the development process: training and validation. The distinction matters more than it might seem.
Training is where a model learns. Here, amplification is useful. If a rare event has been captured once on video, a world foundation model can take that clip and generate many physically coherent variations of it, creating different weather conditions, lighting angles, or actor trajectories. This expands coverage without waiting for the world to produce more examples. Traditional simulators attempt something similar, but they reflect the assumptions of whoever built them. A world model that has been trained on real footage generates variations that remain grounded in how the physical world actually behaves.
Validation is different. Here, fidelity is what matters. You cannot validate a system's behavior against synthetic data alone, because synthetic data reflects assumptions, and the point of validation is to test how the system performs when those assumptions break. Real-world footage, captured across diverse conditions, is what gives validation its credibility.
This training-validation distinction is one reason why scenario generation from real-world clips, rather than from hand-authored simulations, has become such an active area. The goal is not just to produce more data, but to produce data that can serve both functions: expanding training coverage while grounding validation in reality.
A model that has learned from footage collected in one region will have blind spots in places with different road conditions, signage conventions, or driver behavior. Roundabouts, unmarked intersections, mixed pedestrian-vehicle zones, and unusual road markings are all common in some parts of the world and rare in others. A system that has never seen them during training will not know how to handle them.
This is not a corner case. It is a fundamental constraint on generalization. Geographic diversity in training data is not a nice-to-have property. It is what allows a self-driving system to operate reliably beyond the cities it was trained in.
Achieving that diversity through dedicated fleets is expensive and slow. Cities have to be selected, vehicles have to be deployed, and operations have to be maintained, one market at a time. Scaling that model globally is a significant undertaking, and it tends to produce data that reflects urban cores more than the full range of conditions a vehicle will actually encounter.
Crowdsourced, privacy-preserving collection from vehicles already on the road in many countries offers a different model. The coverage is broader by default because the drivers are already there. The challenge shifts from deployment to data quality and pipeline reliability.

NATIX operates as a data infrastructure layer for Physical AI. Through its VX360 multi-camera capture network, NATIX collects structured, privacy-compliant footage from vehicles in the field, across geographies, and feeds that footage through the kind of pipeline described above: ingestion, anonymization, annotation, curation, and delivery in formats that AI teams can actually use.
The partnership with Valeo on an open-source multi-camera world foundation model is a concrete example of how this works in practice. World Foundation Models need multi-angle, real-world footage at scale, not just for training coverage, but for validation. NATIX's surround-view data provides exactly that input: consistent, georeferenced, anonymized clips from real driving conditions across multiple cameras simultaneously.
The world does not happen only in front of the car. Rare events often unfold across angles, and front-facing datasets miss that context. Multi-camera data captures the full scene, which is what makes it useful not just for training perception models, but for grounding the scenario generation and validation workflows that depend on physical coherence.
This is where the pieces come together. VLMs make large archives searchable and useful for annotation and edge-case discovery. World Foundation Models expand coverage by generating grounded variations from real clips. Real-world footage provides the diversity and fidelity that neither simulation nor small fleets can match on their own. The data pipeline connects all three.
The bottleneck in autonomous driving development is not the absence of cameras. It is the absence of good pipelines. A dashcam recording a drive in an unfamiliar city captures something that cannot be scheduled or simulated: real behavior, in real conditions, from an angle that matters. But that recording is only valuable if it can be found, cleaned, annotated, and delivered to the teams building the systems that will eventually drive on those same roads.
What a self-driving system learns depends almost entirely on what happens after the recording ends. The footage is the starting point. The pipeline is what turns it into intelligence. And the companies that invest seriously in that pipeline, not just in the hardware that feeds it, are the ones building systems that can handle the world as it actually is.